









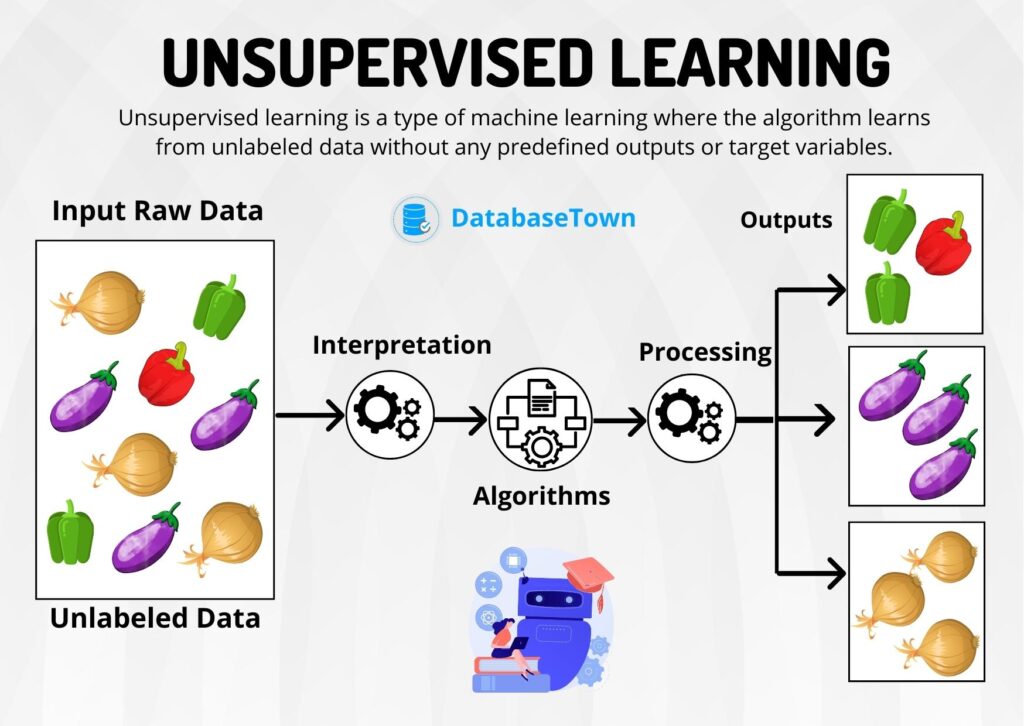
exploringdatascience.com – Di era big data saat ini, machine learning telah menjadi pilar utama dalam pengolahan informasi. Salah satu cabang paling menarik adalah unsupervised learning, yaitu pendekatan di mana algoritma belajar dari data tanpa petunjuk eksplisit berupa label atau jawaban benar. Berbeda dengan supervised learning yang mengandalkan data berlabel untuk prediksi, unsupervised learning fokus pada menemukan struktur, pola, atau hubungan tersembunyi dalam data mentah. Teknik ini sangat berguna ketika kita memiliki dataset besar tapi tidak tahu apa yang harus dicari. Artikel ini akan mengupas tuntas unsupervised learning, mulai dari pengertian dasar, algoritma utama, aplikasi nyata, hingga kelebihan dan tantangannya.
Pengertian dan Prinsip Dasar Unsupervised Learning
Unsupervised learning merupakan bagian dari machine learning di mana model dilatih menggunakan data yang tidak memiliki label output. Tujuannya adalah untuk mengidentifikasi pola intrinsik, seperti kelompok data yang mirip atau representasi data yang lebih sederhana. Proses ini mirip dengan bagaimana manusia mengelompokkan objek tanpa instruksi, misalnya mengategorikan buah-buahan berdasarkan bentuk dan warna.
Prinsip utamanya adalah eksplorasi data. Algoritma mencari fitur-fitur yang membedakan atau menyatukan data points. Hasilnya bisa berupa cluster (kelompok), reduksi dimensi, atau deteksi anomali. Teknik ini sering menjadi langkah awal dalam analisis data, membantu menghasilkan hipotesis untuk tahap selanjutnya.
Jenis-Jenis Utama Unsupervised Learning
Ada dua kategori besar dalam unsupervised learning: clustering dan dimensionality reduction.
Clustering: Mengelompokkan Data yang Mirip
Clustering adalah teknik untuk membagi data menjadi kelompok-kelompok di mana data dalam satu cluster lebih mirip satu sama lain daripada dengan cluster lain.
- K-Means Clustering: Algoritma populer yang membagi data menjadi K cluster dengan meminimalkan jarak ke pusat cluster (centroid). Proses iteratif hingga konvergen.
- Hierarchical Clustering: Membuat pohon hierarki (dendrogram) untuk menunjukkan hubungan antar data, bisa agglomerative (bottom-up) atau divisive (top-down).
- DBSCAN: Berbasis densitas, cocok untuk data dengan bentuk cluster tidak bulat dan bisa mendeteksi noise.
Dimensionality Reduction: Menyederhanakan Data
Teknik ini mengurangi jumlah fitur sambil mempertahankan informasi penting, berguna untuk visualisasi dan mengatasi curse of dimensionality.
- Principal Component Analysis (PCA): Mengubah data ke ruang baru dengan komponen utama yang menangkap variansi maksimal.
- t-SNE dan UMAP: Untuk visualisasi data tinggi dimensi ke 2D/3D, sering digunakan di bioinformatics.
- Autoencoders: Jaringan saraf yang belajar merepresentasikan data dengan kompresi, populer di deep learning.
Aplikasi Unsupervised Learning di Dunia Nyata
Unsupervised learning memiliki aplikasi luas di berbagai bidang:
- Segmentasi Pelanggan: Perusahaan e-commerce mengelompokkan pembeli berdasarkan perilaku untuk rekomendasi personal.
- Deteksi Penipuan: Bank mendeteksi transaksi anomali tanpa contoh penipuan sebelumnya.
- Bioinformatics: Mengelompokkan gen atau protein berdasarkan ekspresi.
- Rekomendasi Sistem: Netflix atau Spotify menggunakan clustering untuk saran konten.
- Pengolahan Gambar: Kompresi gambar atau segmentasi objek.
Kelebihan dan Tantangan Unsupervised Learning
Kelebihan:
- Tidak memerlukan data berlabel, yang sering mahal dan memakan waktu.
- Berguna untuk eksplorasi data dan penemuan insight baru.
- Skalabel untuk data besar.
Tantangan:
- Evaluasi sulit karena tidak ada ground truth; metrik seperti silhouette score digunakan.
- Hasil bisa subyektif dan tergantung parameter (misalnya K di K-Means).
- Sensitif terhadap noise dan outlier.
- Komputasi intensif untuk data sangat besar.
Perkembangan Terkini dan Masa Depan
Dengan kemajuan deep learning, unsupervised learning semakin powerful melalui model seperti variational autoencoders dan self-supervised learning (seperti di BERT atau SimCLR). Teknik ini menjadi fondasi untuk AI yang lebih mandiri, di mana model belajar representasi data tanpa supervisi manusia.
Unsupervised learning membuka pintu untuk memahami data kompleks yang tidak terstruktur, menjadi alat esensial bagi data scientist dan peneliti. Dari clustering sederhana hingga autoencoders canggih, teknik ini terus berkembang dan mendorong inovasi di berbagai sektor. Bagi pemula, mulailah dengan library seperti scikit-learn di Python untuk bereksperimen. Dengan unsupervised learning, kita tidak hanya memprediksi, tapi juga menemukan hal-hal baru yang tersembunyi dalam data.







