
exploringdatascience.com – Ensemble Learning adalah teknik dalam pembelajaran mesin (machine learning) yang menggabungkan beberapa model prediktif untuk menghasilkan prediksi yang lebih akurat dan stabil dibandingkan model tunggal. Pendekatan ini terinspirasi dari konsep kebijaksanaan kolektif, di mana kombinasi keputusan dari berbagai sumber sering kali menghasilkan hasil yang lebih baik daripada keputusan individu. Artikel ini akan membahas konsep dasar, metode utama, kelebihan, dan aplikasi Ensemble Learning.
Konsep Dasar Ensemble Learning
Ensemble Learning bekerja dengan cara mengintegrasikan prediksi dari beberapa model pembelajaran mesin, yang disebut sebagai “base learners” atau “weak learners.” Tujuannya adalah untuk mengurangi bias, varians, atau keduanya, sehingga meningkatkan performa model secara keseluruhan. Ada dua prinsip utama dalam Ensemble Learning:
-
Diversitas: Model-model dalam ensemble harus berbeda satu sama lain, baik dalam algoritma, data pelatihan, atau parameter, untuk menangkap berbagai aspek dari data.
-
Agregasi: Prediksi dari masing-masing model digabungkan, baik melalui pemungutan suara (voting), rata-rata, atau metode lain, untuk menghasilkan keputusan akhir.
Metode Utama Ensemble Learning
Ada beberapa metode populer dalam Ensemble Learning, di antaranya:
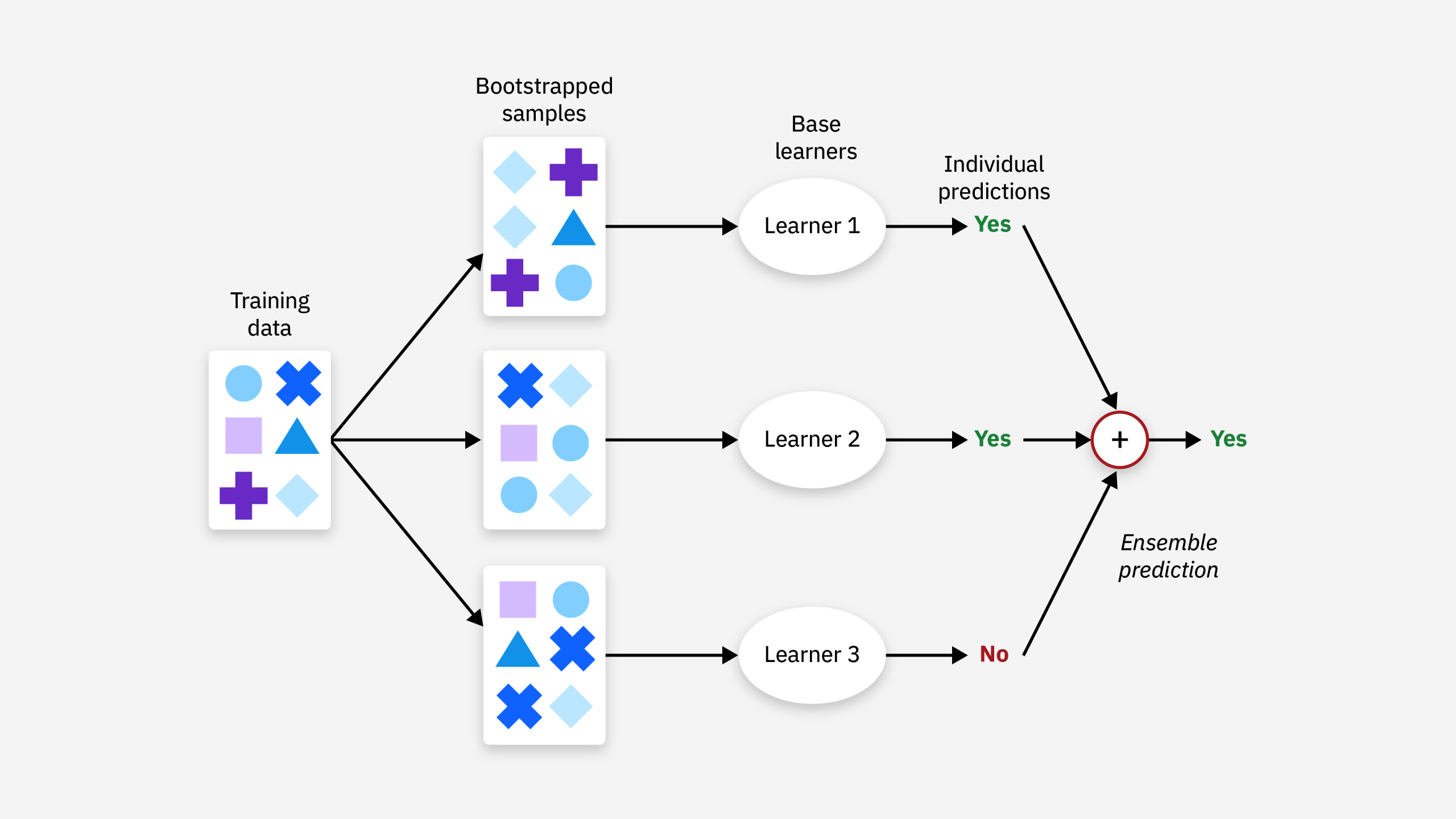
1. Bagging (Bootstrap Aggregating)
Bagging melibatkan pelatihan beberapa model yang sama (misalnya, pohon keputusan) pada subset data yang berbeda, yang diambil secara acak dengan penggantian (bootstrap). Prediksi dari semua model kemudian digabungkan, biasanya dengan rata-rata untuk regresi atau pemungutan suara mayoritas untuk klasifikasi. Contoh algoritma bagging adalah Random Forest, yang menggunakan pohon keputusan sebagai base learner.
2. Boosting
Boosting membangun model secara berurutan, di mana setiap model baru berfokus pada memperbaiki kesalahan prediksi dari model sebelumnya. Data yang salah diprediksi diberi bobot lebih tinggi untuk memastikan model berikutnya lebih memperhatikan kasus-kasus sulit. Contoh algoritma boosting adalah AdaBoost, Gradient Boosting, dan XGBoost.
3. Stacking
Stacking (atau stacked generalization) menggabungkan prediksi dari beberapa model yang berbeda (misalnya, SVM, pohon keputusan, dan regresi logistik) menggunakan model meta-learner. Model dasar menghasilkan prediksi, yang kemudian digunakan sebagai input untuk model meta-learner untuk membuat keputusan akhir.
4. Voting
Voting adalah metode sederhana di mana beberapa model yang berbeda memberikan prediksi, dan keputusan akhir diambil berdasarkan mayoritas (untuk klasifikasi) atau rata-rata (untuk regresi). Voting dapat bersifat “hard” (memilih kelas mayoritas) atau “soft” (menggabungkan probabilitas prediksi).
Kelebihan Ensemble Learning
Ensemble Learning memiliki beberapa keunggulan, di antaranya:
-
Akurasi yang Lebih Tinggi: Dengan menggabungkan berbagai model, ensemble sering kali menghasilkan prediksi yang lebih akurat dibandingkan model tunggal.
-
Stabilitas: Ensemble mengurangi risiko overfitting dengan menurunkan varians model.
-
Fleksibilitas: Dapat digunakan dengan berbagai jenis algoritma dan data, menjadikannya cocok untuk berbagai masalah.
-
Kemampuan Menangani Data Kompleks: Ensemble efektif untuk dataset besar atau dengan pola yang rumit.
Kekurangan Ensemble Learning
Meski memiliki banyak kelebihan, Ensemble Learning juga memiliki beberapa kelemahan:
-
Kompleksitas Komputasi: Membutuhkan sumber daya komputasi yang lebih besar karena melibatkan pelatihan beberapa model.
-
Interpretasi yang Sulit: Model ensemble, seperti Random Forest atau XGBoost, sering kali sulit diinterpretasikan dibandingkan model tunggal seperti regresi linear.
-
Waktu Pelatihan yang Lama: Proses pelatihan bisa memakan waktu lebih lama, terutama pada dataset besar.
Aplikasi Ensemble Learning
Ensemble Learning telah digunakan secara luas di berbagai bidang, termasuk:
-
Keuangan: Untuk mendeteksi penipuan kartu kredit atau memprediksi harga saham.
-
Kesehatan: Untuk mendiagnosis penyakit berdasarkan data medis, seperti deteksi kanker.
-
Pemasaran: Untuk memprediksi perilaku pelanggan atau segmentasi pasar.
-
Kompetisi Data Science: Banyak pemenang kompetisi seperti Kaggle menggunakan teknik ensemble untuk mencapai performa terbaik.
Contoh Implementasi
Berikut adalah contoh sederhana implementasi Random Forest menggunakan Python dan library scikit-learn:
from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score.