

exploringdatascience.com – Q-Learning adalah salah satu algoritma paling fundamental dalam bidang Reinforcement Learning (RL). Dikembangkan oleh Chris Watkins pada tahun 1989, Q-Learning termasuk dalam kategori model-free dan off-policy RL, yang berarti algoritma ini belajar nilai optimal dari tindakan tanpa perlu membangun model lingkungan secara eksplisit dan bisa belajar dari kebijakan yang berbeda dari kebijakan yang sedang dieksekusi. Hingga 2025, Q-Learning tetap menjadi dasar penting bagi banyak algoritma RL modern seperti Deep Q-Network (DQN) yang digunakan di AlphaGo dan game AI lainnya.
Ilustrasi agen yang belajar melalui trial-and-error dalam lingkungan grid world menggunakan Q-Learning.
Prinsip Dasar Q-Learning
Q-Learning bekerja berdasarkan konsep Q-value atau action-value function, yaitu nilai harapan reward jangka panjang jika agen mengambil tindakan tertentu di state tertentu, lalu mengikuti kebijakan optimal setelahnya. Secara matematis, Q-value didefinisikan sebagai:
Q(s,a)=E[Rt+γmaxa′Q(s′,a′)∣st=s,at=a] Q(s, a) = \mathbb{E} \left[ R_t + \gamma \max_{a’} Q(s’, a’) \mid s_t = s, a_t = a \right]
Di mana:
- ss: state saat ini
- aa: action yang diambil
- s′s’: state berikutnya
- RtR_t: reward langsung
- γ\gamma: discount factor (0 ≤ γ < 1), menentukan seberapa penting reward masa depan
Algoritma ini memperbarui Q-table secara iteratif menggunakan Bellman equation:
Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)] Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r + \gamma \max_{a’} Q(s’, a’) – Q(s, a) \right]
Di mana α adalah learning rate.
Persamaan update Q-Learning yang menjadi inti algoritma.
Langkah-langkah Algoritma Q-Learning
- Inisialisasi Q-table dengan nilai nol atau random untuk semua pasangan (state, action).
- Pada setiap episode:
- Amati state saat ini ss.
- Pilih action aa menggunakan kebijakan eksplorasi, misalnya ε-greedy (dengan probabilitas ε pilih random, sisanya pilih action dengan Q-value tertinggi).
- Eksekusi action, amati reward rr dan state baru s′s’.
- Update Q-value menggunakan rumus di atas.
- Set s←s′s \leftarrow s’.
- Ulangi hingga konvergen atau batas episode tercapai.
Diagram flowchart sederhana proses Q-Learning.
Kelebihan Q-Learning
- Off-policy: Bisa belajar kebijakan optimal meski agen menggunakan kebijakan eksplorasi yang berbeda.
- Model-free: Tidak perlu tahu transisi probabilitas lingkungan.
- Konvergen terjamin pada lingkungan Markov Decision Process (MDP) finite dengan eksplorasi yang cukup dan learning rate yang menurun secara tepat.
- Mudah diimplementasikan untuk masalah dengan state-action space yang tidak terlalu besar.
Kelemahan dan Tantangan
- Curse of dimensionality: Q-table membengkak eksponensial seiring bertambahnya jumlah state dan action (tidak skalabel untuk masalah besar).
- Overestimation bias: Karena penggunaan max operator, Q-value cenderung overestimate.
- Eksplorasi vs eksploitasi: Perlu balancing yang baik agar tidak terjebak di local optima.
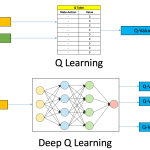
Solusi modern untuk kelemahan ini adalah Deep Q-Network (DQN) yang menggantikan Q-table dengan neural network, serta varian seperti Double DQN, Dueling DQN, dan Prioritized Experience Replay.
Perbandingan Q-Learning klasik (table-based) vs Deep Q-Network (function approximation).
Contoh Aplikasi Q-Learning
- Grid World: Agen belajar mencari jalan terpendek ke tujuan sambil menghindari rintangan.
- Taxi Problem (OpenAI Gym): Agen belajar mengantar penumpang ke tujuan dengan reward/penalty.
- Game klasik: Atari games (via DQN), Frozen Lake, CartPole.
- Robotika: Navigasi robot di lingkungan tidak diketahui.
- Keuangan: Trading otomatis dengan reward berbasis profit.
Q-Learning adalah fondasi penting dalam Reinforcement Learning yang membuka jalan bagi algoritma RL modern berbasis deep learning. Meski memiliki keterbatasan pada masalah berskala besar, pemahaman mendalam tentang Q-Learning sangat esensial bagi siapa pun yang ingin berkecimpung di bidang AI dan machine learning. Di tahun 2025, konsep ini tetap relevan sebagai starting point untuk memahami bagaimana agen bisa belajar dari interaksi dengan lingkungan secara mandiri.