
exploringdatascience.com – Random Forest adalah salah satu algoritma pembelajaran mesin (machine learning) yang paling populer dan serbaguna, dikenal karena kemampuannya menghasilkan prediksi yang akurat dan stabil dalam berbagai aplikasi. Berbasis pada konsep ensemble learning, Random Forest menggabungkan kekuatan banyak pohon keputusan (decision trees) untuk mengatasi kelemahan model tunggal.
Apa Itu Random Forest?
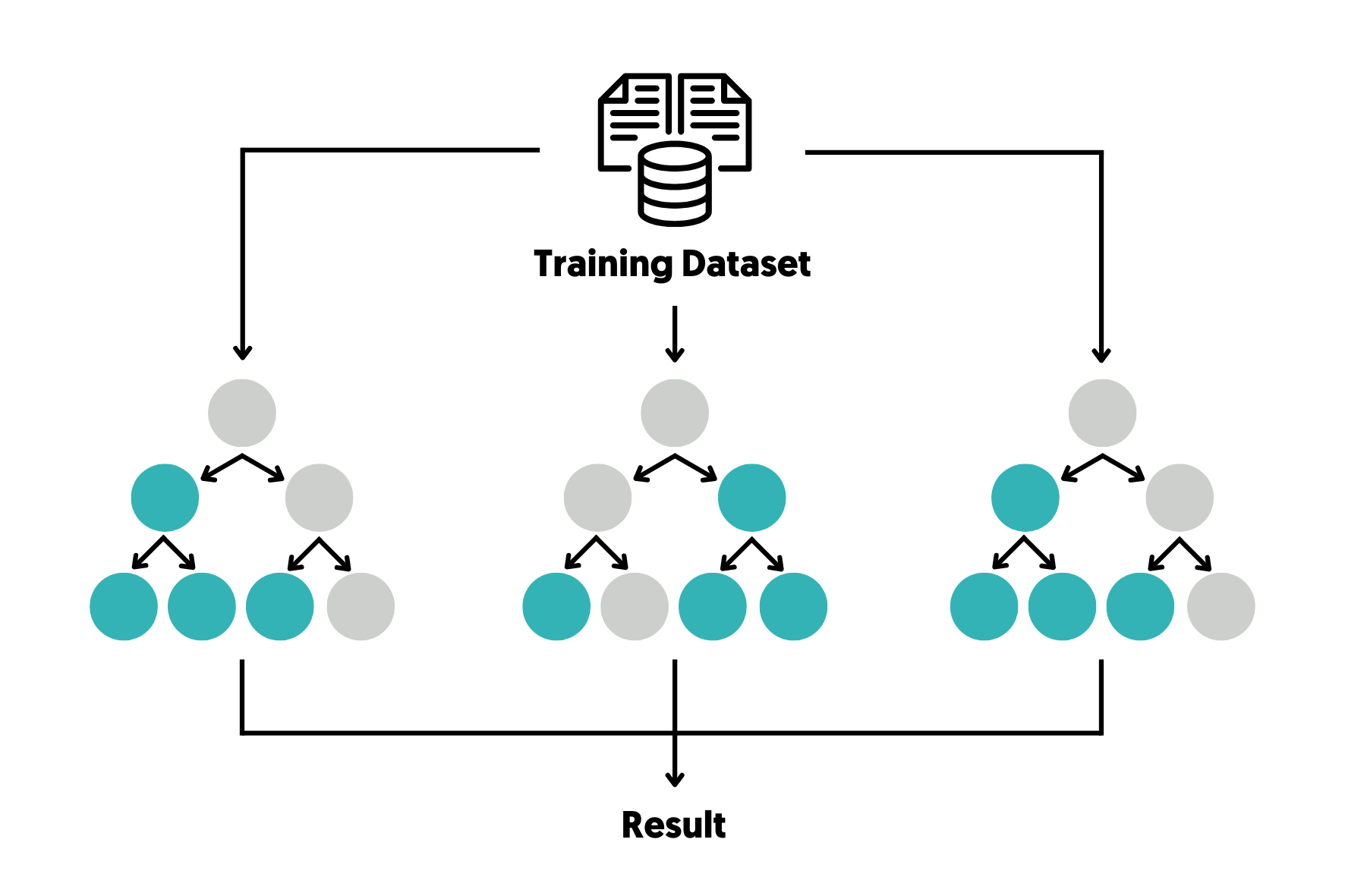
Random Forest, yang diperkenalkan oleh Leo Breiman pada tahun 2001, adalah algoritma supervised learning yang digunakan untuk tugas klasifikasi dan regresi. Algoritma ini bekerja dengan membangun sejumlah besar pohon keputusan, masing-masing dilatih pada subset acak dari data dan fitur. Hasil dari setiap pohon kemudian digabungkan—melalui voting untuk klasifikasi atau rata-rata untuk regresi—untuk menghasilkan prediksi akhir yang lebih akurat dan tahan terhadap overfitting.
Nama “Random Forest” berasal dari dua elemen kunci:
-
Random: Pengacakan dalam pemilihan data (bootstrap sampling) dan fitur untuk setiap pohon.
-
Forest: Kumpulan banyak pohon keputusan yang bekerja bersama.
Bagaimana Random Forest Bekerja?
Proses kerja Random Forest dapat dirangkum dalam langkah-langkah berikut:
-
Bootstrap Sampling: Algoritma mengambil subset acak dari data pelatihan dengan penggantian (bootstrap), sehingga beberapa data dapat muncul lebih dari sekali, sementara yang lain mungkin tidak terpilih.
-
Pemilihan Fitur Acak: Untuk setiap pohon, hanya subset acak dari fitur yang dipertimbangkan saat membagi node, meningkatkan keragaman antar pohon.
-
Pembangunan Pohon Keputusan: Setiap pohon dilatih secara independen pada subset data dan fitur yang berbeda.
-
Agregasi Hasil: Untuk klasifikasi, prediksi akhir diambil berdasarkan mayoritas suara dari semua pohon. Untuk regresi, rata-rata prediksi digunakan.
Pengacakan ini membuat Random Forest tahan terhadap noise dan overfitting, sekaligus memastikan model tetap robust meskipun data memiliki banyak fitur atau kompleksitas tinggi.
Keunggulan dan Kelemahan Random Forest
Keunggulan:
-
Akurasi Tinggi: Dengan menggabungkan banyak pohon, Random Forest sering mengungguli algoritma lain seperti pohon keputusan tunggal atau regresi logistik.
-
Tahan Overfitting: Pengacakan data dan fitur mengurangi risiko model terlalu cocok dengan data pelatihan.
-
Fleksibel: Dapat digunakan untuk klasifikasi (misalnya, mendeteksi spam email) dan regresi (misalnya, memprediksi harga rumah).
-
Penanganan Data yang Buruk: Mampu menangani data yang hilang, fitur kategorikal, dan data dengan skala berbeda tanpa banyak pra-pemrosesan.
-
Feature Importance: Random Forest dapat menunjukkan fitur mana yang paling berpengaruh dalam prediksi, membantu analisis data.
Kelemahan:
-
Kompleksitas Komputasi: Membutuhkan sumber daya komputasi yang besar, terutama untuk dataset besar dengan banyak pohon.
-
Interpretasi Sulit: Meskipun memberikan feature importance, logika keputusan keseluruhan sulit dijelaskan dibandingkan model sederhana seperti regresi linier.
-
Waktu Pelatihan: Pelatihan bisa lambat untuk dataset besar karena banyaknya pohon yang dibangun.
Aplikasi Random Forest di Dunia Nyata
Random Forest telah terbukti efektif di berbagai bidang:
-
Keuangan: Digunakan untuk mendeteksi penipuan kartu kredit dengan mengenali pola transaksi yang mencurigakan.
-
Kesehatan: Membantu mendiagnosis penyakit, seperti kanker, berdasarkan data medis seperti hasil laboratorium atau gambar pemindaian.
-
E-commerce: Memprediksi perilaku pelanggan, seperti kemungkinan pembelian atau churn, untuk strategi pemasaran yang lebih baik.
-
Ekologi: Digunakan untuk memprediksi distribusi spesies atau dampak perubahan iklim berdasarkan data lingkungan.
-
Keamanan Siber: Mengidentifikasi ancaman siber dengan menganalisis pola lalu lintas jaringan.
Implementasi Praktis
Random Forest tersedia di banyak pustaka machine learning, seperti scikit-learn (Python), caret (R), dan H2O. Contoh sederhana dalam Python menggunakan scikit-learn:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Contoh data
X, y = load_data() # Ganti dengan dataset Anda
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Inisialisasi dan latih model
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
# Prediksi dan evaluasi
y_pred = rf.predict(X_test)
print("Akurasi:", accuracy_score(y_test, y_pred))Parameter seperti n_estimators (jumlah pohon) dan max_depth (kedalaman pohon) dapat disesuaikan untuk mengoptimalkan performa.
Masa Depan Random Forest
Meskipun algoritma seperti deep learning mendominasi untuk data kompleks seperti gambar atau teks, Random Forest tetap relevan karena kesederhanaannya, efisiensi pada dataset terstruktur, dan kemampuan menangani berbagai jenis masalah. Inovasi seperti Extremely Randomized Trees atau integrasi dengan teknik ensemble lain terus meningkatkan kegunaannya.
Selain itu, Random Forest sering digunakan sebagai baseline dalam kompetisi machine learning seperti Kaggle karena keandalannya. Dengan munculnya AutoML, Random Forest juga menjadi bagian dari alur kerja otomatis untuk memilih model terbaik.
Random Forest adalah alat yang kuat dan mudah digunakan dalam kotak peralatan machine learning, menawarkan keseimbangan antara akurasi, fleksibilitas, dan kemudahan implementasi. Baik untuk pemula yang baru belajar ML atau profesional yang menangani masalah kompleks, Random Forest tetap menjadi pilihan utama karena kemampuannya menghasilkan hasil yang andal dengan sedikit penyesuaian.
Bagi mereka yang ingin mendalami, sumber daya seperti dokumentasi scikit-learn, kursus online, atau komunitas seperti Kaggle menyediakan banyak kesempatan untuk bereksperimen dengan Random Forest. Di era data-driven saat ini, memahami algoritma seperti ini adalah langkah penting menuju pengambilan keputusan yang lebih cerdas dan inovatif.