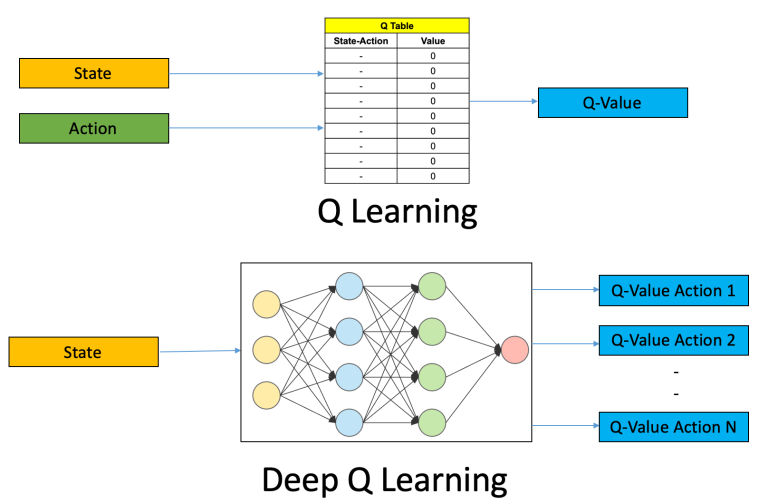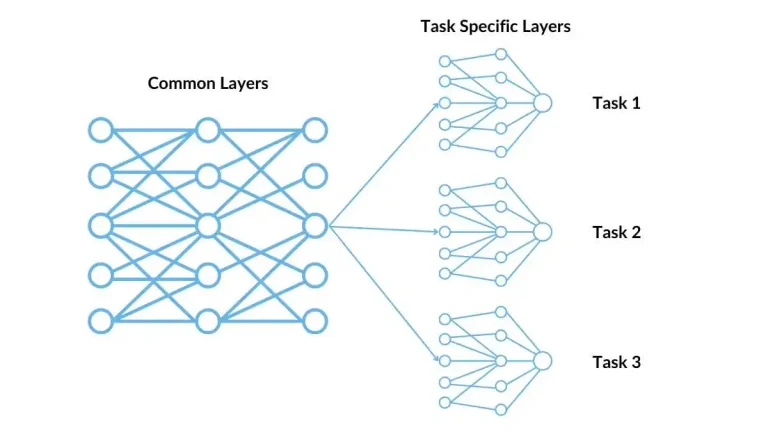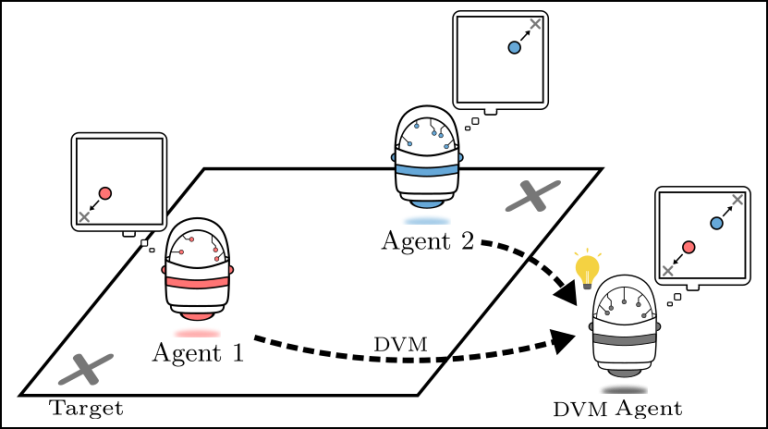

exploringdatascience.com – Dalam era kecerdasan buatan yang semakin kompleks, interpretabilitas model machine learning menjadi aspek krusial untuk memastikan kepercayaan dan akuntabilitas. Model yang dapat dijelaskan memungkinkan pengguna memahami alasan di balik prediksi, yang penting dalam bidang seperti kesehatan, keuangan, dan hukum.
Terdapat dua pendekatan utama dalam interpretabilitas: intrinsik dan post-hoc. Model intrinsik, seperti pohon keputusan dan regresi linier, secara alami lebih mudah dipahami. Sementara itu, teknik post-hoc digunakan untuk menjelaskan model kompleks seperti jaringan saraf dalam. Metode populer termasuk LIME (Local Interpretable Model-agnostic Explanations) dan SHAP (SHapley Additive exPlanations), yang membantu mengidentifikasi fitur mana yang paling mempengaruhi prediksi model.
Perkembangan terbaru juga mencakup penggunaan alat seperti Captum untuk model PyTorch, yang menyediakan berbagai metode atribusi untuk interpretasi prediksi model. Selain itu, pendekatan Pairwise Shapley Values menawarkan cara baru untuk memahami kontribusi fitur dengan membandingkan pasangan data yang serupa, meningkatkan interpretabilitas sambil mengurangi beban komputasi.
Dengan meningkatnya regulasi dan kebutuhan akan transparansi, interpretabilitas model machine learning tidak hanya menjadi nilai tambah, tetapi juga kebutuhan. Implementasi teknik-teknik ini membantu memastikan bahwa sistem AI beroperasi secara adil dan dapat dipercaya, mendukung adopsi yang lebih luas dalam berbagai sektor industri.